

Over the past few months, we fundamentally overhauled the backend behind the Hetzner Cloud Server API, including a separate database with a new structure. Why? A growing company like Hetzner has to modernize and reorganize certain processes and technical infrastructure – and that applies to our internal systems too.
Our goal was for you, as a customer, to notice nothing at all. Behind the scenes, though, we faced a major challenge: building software that behaves exactly like the old system. To get there, the new system had to be tested thoroughly.
Rewriting some software from scratch always has its challenges. It's a huge effort, countless hours have been invested in the old system. There's usually also a lot of hidden knowledge in the old software, code to handle rare special cases, or code to ensure good performance under extraordinary conditions. In our case an important requirement was, that the new software should functionally behave in the same way as the old software.
In this article, we show you how property-based testing inspired our approach, and why we used random sequences of API calls to test the new backend before its release.
Why unit tests and manual testing aren’t enough for a backend rewrite
So what are the options for testing new software? Here are a few examples.
Automated or manual tests: Automated tests are run and evaluated by a computer, while manual tests are carried out by a person using the product.
Functional or non-functional tests: Functional tests make sure the software behaves according to its specification. Non-functional tests evaluate other requirements such as performance, stability, and usability.
Deterministic or random tests: Unit and integration tests are usually deterministic: we write down a sequence of actions and compare the result against an expected outcome. If the expectation is met, the test passes. Random tests – as the name suggests – add some randomness into testing. In some scenarios it’s as simple as reading random data from /dev/urandom.
Most of these classic approaches share one limit, though: they mainly test predefined scenarios, not the endless variety of combinations that can occur in practice. With an API, the number of individual actions is manageable. But combine them, and the number of possible action chains grows exponentially.
We needed a more structured way to define what “random” means, and this is where property-based testing comes into play.
What is property-based testing – and how does it work?
Property-based testing is a method of automatically checking that certain properties of a program hold for many randomly generated inputs. It’s an automated, functional and random testing approach.
A property-based test consists of the following core elements:
- Generators
- Properties
- Shrinkers
We’ll explore these step-by-step with an example use case. Let’s assume we’re programming a sorting algorithm for integers and want to test it with random input.
A generator produces many random lists of integers and feeds them to the algorithm one after another. After each run, the test checks whether the result meets the defined rules: the output list must be the same length as the input, contain the same numbers, and be correctly sorted. If any of these rules is violated, the test fails. When the system finds a bug, the shrinker simplifies the faulty list step by step until only a minimal counter-example remains – one that makes the bug easier to trace and, ideally, to reproduce.
To make this more concrete, let’s take our own case as an example.
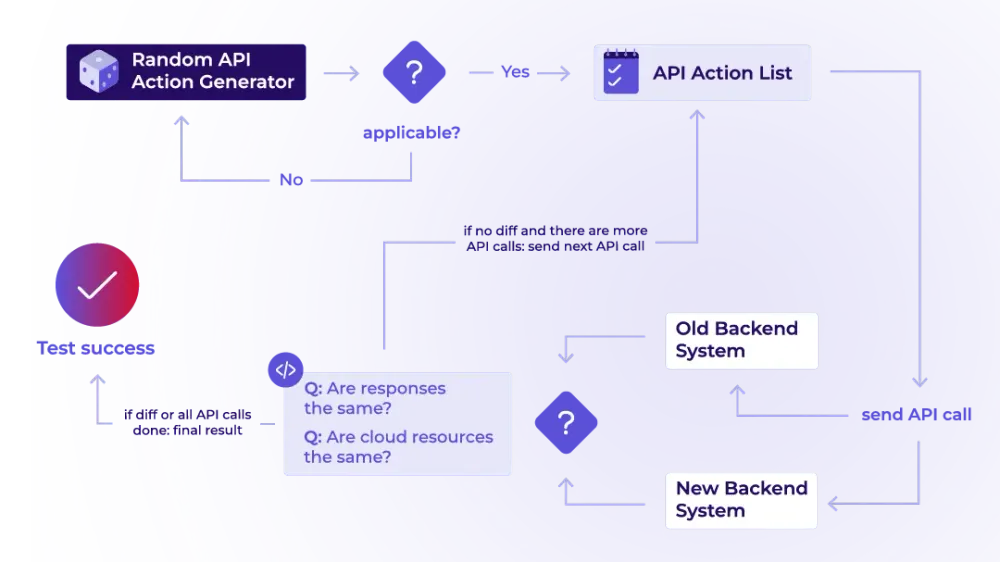
Our central property was this: the new backend has to respond to every request exactly like the old one. We could have implemented this check ourselves, but since our case mapped so neatly onto property-based testing, we used an existing property-based testing library instead.
Generators: how they automatically create random but valid API calls
The generator produces the API requests. Randomness matters here: users can be remarkably creative in how they use our API, and there’s no way for us to anticipate every possible combination and usage pattern, let alone test them all deliberately. On top of that, even a handful of different actions makes the number of possible action chains grow exponentially.
A problem showed up quickly: a random ordering often contains actions that aren’t possible in the current state. A “start server” action, for example, can only succeed once a server exists. So we added an applicability check: it discards non-applicable actions until a valid one remains.
Our API action generator handled the rest. It generated valid calls based on three pieces of information:
- The parameters that exist
- The allowed values
- The conditions under which an action is applicable
Properties: the rules that decide whether a test passes or fails
With that information in hand, our next step was to determine exactly which properties we wanted to test. We compared the new backend against the old one to see whether both behaved the same.
Here we deviated slightly from classic property-based testing. Normally, one property check runs per input. In our backend test, by contrast, we ran a check after every single API call. If the generator produced a sequence of ten API calls, ten property checks ran with it: one after the first call, one after the second, and so on. From a theoretical perspective, that would not have been necessary, because a random generator would eventually generate any sublist as a standalone test. However, from a practical point of view, it gave us more test coverage in a single test run.
# rough outline of the property check loop in Python-like syntax# - steps is the randomly generated list of API calls# - backend_old/new are references to Hetzner Cloud using the old and new backendfor step in steps:# send the API call to both backend systemsresult_old = step.run(backend_old)result_new = step.run(backend_new)# check whether both backend systems returned the same API responseresponse_diff = compare_api_response(result_old, result_new)if response_diff:print(f"Found response diff: {response_diff}")return False# check whether resources (servers, volumes, ...) are the same# in both backend systemsresources_diff = compare_cloud_projects(backend_old, backend_new)if resources_diff:print(f"Found resources diff: {resources_diff}")return False# if after all steps there was no error, the test is a successreturn True
The checks themselves were quite simple. First, we compared the API response from both backend systems. As soon as the responses differed, the test was marked as failed.
If the API responses matched, the next step was to check the state of the resources. To do that, we queried servers and other related resources, such as volumes, from both backends and compared them one by one. Almost all attributes had to match. The only exceptions were fields like IDs or timestamps: because the two backends worked independently of each other, these values couldn’t be guaranteed to be identical. As soon as a comparable field diverged, the test was likewise marked as failed.
Shrinkers: how we reduced bugs to their smallest reproducible core
When a test failed, the shrinker tried to reduce the input that triggered the failure. In our case, that input was usually a list of API calls. The goal was to make the failing case smaller and easier to understand.
We did not invest too much time into shrinking. Even so, the default list shrinker was still useful.
Many of our API calls involved communication with real hardware. In our tests, both backend systems were connected to real hosts, and we created functional servers. This created a few challenges for shrinking.
The first challenge was the duration of each shrinking step. Compared to something like a sorting algorithm, our test was extremely slow. Many API calls changed the state of a cloud server, which took some time. A full sequence of API calls could therefore take seconds or minutes, depending on the API calls and the length of the list. And that time was required for each shrinking step.
The second challenge was unreproducible errors. In a system involving real hardware, some failures can always happen. The shrinking algorithm, however, assumes that all errors are perfectly reproducible. Sometimes, this led to long shrinking attempts caused by a non-reproducible error. One example: When a user enabled the Rescue System on a server and then — before the reboot — tried to detach an ISO from the same server without an ISO attached, the server’s rescue flag was set back to false. Shrinking minimized the original sequence of API calls to three simple instructions, so we could easily reproduce and fix it:
- Create a server
- Enable Rescue System
- Detach the ISO.
In hindsight, we could have improved shrinking with a few custom adjustments to the default shrinker. For example, if we have a list of ten API calls and detect an error after the fifth API call, we could tell the shrinker to immediately shorten the list to the first five elements. However, even without adjustments, it worked sufficiently well.
What our tests revealed
The approach paid off. We ran into a whole range of discrepancies, including:
- Internal errors, where it was possible to reach a state that was not expected in the backend
- Different states between the old and new backend under error conditions, for example when sending a reset to a server without any IP address: the server was off in the old backend and on in the new backend
- Cases where the new backend allowed more actions than the old backend, for example assigning an IPv6 floating IP without an IPv6 primary
- Different error messages between the old and new backend
- Different states after combining several successful actions, for example rescue after change_type or rescue combined with ISO
With classic or manual tests, we might not have found some of these at all. They only became visible because of the unusual action chains the generator threw together on its own.

After the release: testing without the old backend
After the rollout, the old backend was no longer available as an oracle — that is, as the reference we could check the expected behavior against. So we implemented an internal model of the expected state. For example, after a server start API call, the internal model of the server is updated to running. If the real system state does not match the internal model, we can output an error because our expectation failed. We can also verify changes inside the server now — for example, whether a volume is visible inside the server after a volume attach.
This way, even without the old backend system, we can compare the real system state against our expected state.
Why property-based testing proved its worth for our backend rewrite
For our rewrite, property-based testing proved a valuable building block of quality assurance. The automated, random, and functional approach found problems we’d probably never have noticed with manual or deterministic tests. That let us catch and fix potential bugs in API workflows before the release.
The method worked especially well for this kind of rewrite because we could use the old backend system as an oracle. Shrinking helped reduce failing sequences to smaller examples that were easier to reproduce and fix.
We could still improve shrinking with a few custom adjustments to the default shrinker. Even without those adjustments, however, it worked sufficiently well.




