

In den vergangenen Monaten haben wir das Backend für die Hetzner Cloud Server API grundlegend erneuert, einschließlich einer separaten Datenbank mit neuer Struktur. Warum? Ein wachsendes Unternehmen wie Hetzner muss bestimmte Prozesse und technische Infrastrukturen modernisieren und reorganisieren – das betrifft auch unsere internen Systeme.
Unser Ziel war es, dass du als Kunde davon nichts mitbekommst. Hinter den Kulissen standen wir jedoch vor großen Herausforderungen. Der Anspruch: eine Software zu entwickeln, die exakt dasselbe Verhalten zeigt wie die alte. Um das zu erreichen, musste das neue System umfangreich getestet werden.
Ein grundlegender Rewrite ist immer eine Herausforderung. In der alten Software steckt oft verstecktes Wissen: Code für seltene Sonderfälle oder für gute Performance unter Ausnahmebedingungen. Genau dieses Verhalten durfte sich nicht ändern.
In diesem Artikel zeigen wir dir, wie uns Property-Based Testing inspiriert hat und warum wir zufällige Sequenzen von API-Calls verwendet haben, um unser neues Backend-System vor seiner Veröffentlichung zu testen.
Warum Unit-Tests und manuelle Tests beim Backend-Rewrite nicht ausreichen
Welche Möglichkeiten gäbe es denn, eine neue Software zu testen? Hier sind einige Beispiele:
Automatisierte oder manuelle Tests: Automatisierte Tests werden von einem Computer ausgeführt und ausgewertet, während manuelle Tests von einer Person durchgeführt werden, die das Produkt benutzt.
Funktionale oder nicht-funktionale Tests: Funktionale Tests stellen sicher, dass sich die Software gemäß ihrer Spezifikation verhält. Nicht-funktionale Tests bewerten andere Anforderungen wie Performance, Stabilität oder Usability.
Deterministische oder zufällige Tests: Unit-Tests und Integrationstests sind normalerweise deterministisch: Wir schreiben eine Sequenz von Aktionen auf und vergleichen das Ergebnis mit einem erwarteten Resultat. Wenn die Erwartung erfüllt ist, gilt der Test als bestanden. Zufällige Tests bringen eine gewisse „Randomness“ ins Testen. In manchen Szenarien ist das so einfach wie das Lesen zufälliger Daten aus /dev/urandom.
Der Großteil dieser klassischen Ansätze hat allerdings eine Grenze: Sie testen vor allem vordefinierte Szenarien, nicht die unendliche Vielfalt an Kombinationen, die in der Praxis auftreten kann. Bei einer API ist die Zahl der einzelnen Aktionen überschaubar. Kombinierst du sie aber, wächst die Zahl der möglichen Aktionsketten exponentiell.
Wir haben deshalb drei Ansätze kombiniert: automatisiert, funktional und zufällig. Was „zufällig“ dabei genau heißt, haben wir über eine klare Struktur definiert – und dabei half uns Property-Based Testing.
Was ist Property-Based Testing – und wie funktioniert es?
Ein Beispiel außerhalb unseres Falls macht das greifbarer: Stell dir vor, du möchtest testen, ob ein Sortieralgorithmus richtig funktioniert. Dafür erzeugt ein Generator viele zufällige Zahlenlisten und gibt sie nacheinander an den Algorithmus weiter. Nach jedem Durchlauf prüft der Test, ob das Ergebnis die festgelegten Regeln erfüllt: Die ausgegebene Liste muss genauso lang sein wie die Eingabe, dieselben Zahlen enthalten und richtig sortiert sein. Ist eine dieser Regeln verletzt, gilt der Test als fehlgeschlagen. Findet das System einen Fehler, vereinfacht der Shrinker die fehlerhafte Liste Schritt für Schritt, bis ein möglichst kleines Beispiel übrigbleibt, mit dem sich der Fehler besser nachvollziehen und im Idealfall reproduzieren lässt.
Um dir das besser zu veranschaulichen, nehmen wir unseren Fall als Beispiel.
Unser zentrales Beispiel für so eine Property: Das neue Backend muss auf jede Anfrage exakt so antworten wie das alte. Diese Prüfung hätten wir selbst implementieren können. Da sich unser Fall aber gut für Property-Based Testing eignete, nutzten wir dafür eine bestehende Property-Based-Testing-Bibliothek.
Generators: Wie sie zufällige, aber gültige API-Calls automatisch erzeugen
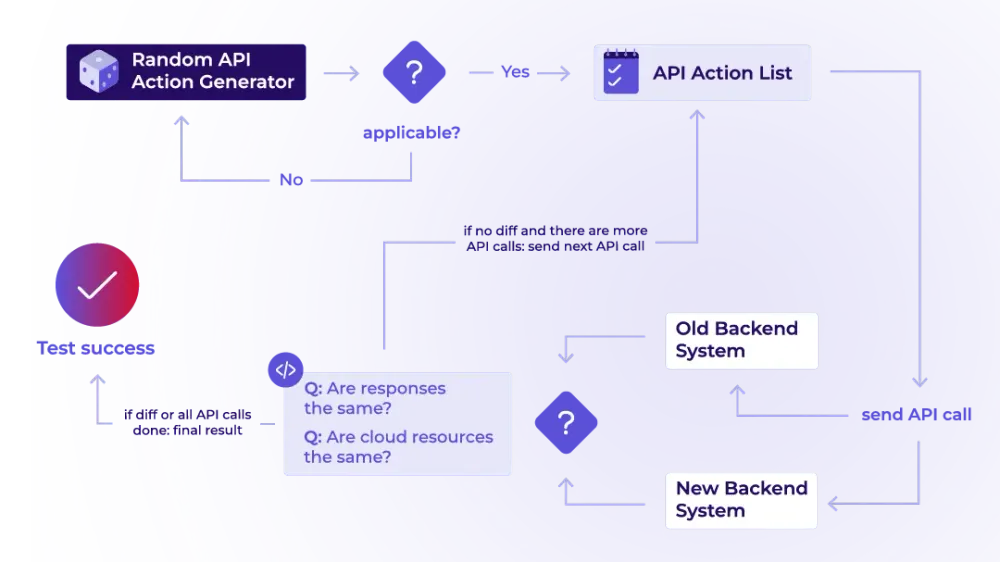
Der Generator erzeugt die API-Anfragen. Der Zufallsgenerator ist sehr wichtig, da User recht kreativ sind bei ihren API-Nutzungsmustern und es uns gar nicht möglich ist, alle möglichen Kombinationen und Nutzungsmuster im Vorfeld zu kennen oder gezielt zu testen. Außerdem wächst schon bei wenigen unterschiedlichen Aktionen die Anzahl der möglichen Aktionsketten exponentiell an.
Ein Problem trat schnell auf: Eine zufällige Reihenfolge enthält oft Aktionen, die im aktuellen Zustand nicht möglich sind. Zum Beispiel kann die Aktion „Server starten“ erst gelingen, wenn ein Server existiert. Daher bauten wir einen Applicability-Check ein: Er verwirft nicht anwendbare Aktionen so lange, bis eine gültige übrigbleibt.
Den Rest übernahm unser API-Action-Generator. Er schickte die Calls an beide Backends, das alte und das neue, und definierte sie nach drei Kriterien:
- Existierende Parameter
- Erlaubte Werte
- Bedingungen, unter denen eine Aktion gültig ist
Properties: Die Regeln, die entscheiden, ob ein Test besteht oder fehlschlägt
Mit dem Input mussten wir als Nächstes festlegen, welche Eigenschaften wir konkret prüfen wollten. Wir haben das neue Backend mit dem alten verglichen, um zu sehen, ob sich beide gleich verhalten
Dabei wichen wir an einer Stelle leicht vom klassischen Property-Based Testing ab. Normalerweise wird pro Eingabe ein Property Check ausgeführt. Bei unserem Backend-Test prüften wir dagegen nach jedem einzelnen API-Call. Erzeugte der Generator zum Beispiel eine Sequenz aus zehn API-Calls, liefen auch zehn Property Checks: einer nach dem ersten Call, einer nach dem zweiten und so weiter. Theoretisch hätten wir auch nur am Ende einer Sequenz prüfen können. Praktisch brachte uns dieser Ansatz aber in einem einzigen Testlauf mehr Vergleichspunkte zwischen altem und neuem Backend.
# rough outline of the property check loop in Python-like syntax# - steps is the randomly generated list of API calls# - backend_old/new are references to Hetzner Cloud using the old and new backendfor step in steps:# send the API call to both backend systemsresult_old = step.run(backend_old)result_new = step.run(backend_new)# check whether both backend systems returned the same API responseresponse_diff = compare_api_response(result_old, result_new)if response_diff:print(f"Found response diff: {response_diff}")return False# check whether resources (servers, volumes, ...) are the same# in both backend systemsresources_diff = compare_cloud_projects(backend_old, backend_new)if resources_diff:print(f"Found resources diff: {resources_diff}")return False# if after all steps there was no error, the test is a successreturn True
Die Checks selbst waren vergleichsweise simpel. Zuerst verglichen wir die API-Response beider Backend-Systeme. Sobald sich die Antworten unterschieden, galt der Test als fehlgeschlagen.
Stimmten die API-Responses überein, prüften wir im nächsten Schritt den Zustand der Ressourcen. Dafür fragten wir bei beiden Backends Server und weitere zugehörige Ressourcen wie Volumes ab und verglichen sie einzeln miteinander. Dabei mussten fast alle Attribute übereinstimmen. Ausgenommen waren nur Felder wie IDs oder Timestamps, da beide Backends unabhängig voneinander arbeiteten und diese Werte daher nicht zwangsläufig identisch sein konnten. Sobald ein vergleichbares Feld abwich, galt der Test ebenfalls als fehlgeschlagen.
Shrinkers: Wie wir Fehler auf ihren kleinsten reproduzierbaren Kern reduziert haben
Schlägt ein Test fehl, kommt der Shrinker zum Einsatz. Seine Aufgabe ist es, die fehlerauslösende Eingabe schrittweise zu verkleinern, um die eigentliche Ursache sichtbar zu machen.
Tritt ein Fehler auf, ist die ursprüngliche Eingabe oft komplex: lange Sequenzen von API-Calls oder viele Parameterwerte. Der Shrinker reduziert diese Eingabe Schritt für Schritt. Er entfernt einzelne Calls oder vereinfacht Parameter und prüft danach, ob der Fehler noch auftritt.
Bleibt er bestehen, verkleinert er weiter, bis nur noch überschaubare Calls übrigbleiben, mit denen sich der Fehler besser nachvollziehen und im Idealfall reproduzieren lässt. Dieses kompakte Beispiel erleichtert das Debugging erheblich.
Eigene Shrinking-Strategien haben wir kaum gebaut. Trotzdem half uns schon der standardmäßige „list shrinker“ enorm. In unserem Fall war das Shrinking recht zeitintensiv, weil die Tests reale Hardware ansprachen: Viele Operationen dauerten länger als bei einem einfachen Algorithmus-Test. Eine komplette Sequenz konnte je nach API-Calls und Länge Sekunden oder Minuten dauern. Und manche Fehler waren nicht perfekt reproduzierbar.
Ein Beispiel: Aktivierte ein Nutzer das Rescue-System auf einem Server und versuchte dann – noch vor dem Neustart –, ein ISO von demselben Server zu entfernen, obwohl dort kein ISO angehängt war, wurde der Rescue-Status des Servers auf false zurückgesetzt. Durch Shrinking wurde die ursprüngliche Sequenz von API-Calls auf drei einfache Schritte reduziert, sodass wir den Fehler leicht reproduzieren und beheben konnten:
- Server erzeugen
- Rescue aktivieren
- ISO detachen
Rückblickend hätten wir Shrinking mit ein paar eigenen Anpassungen am Default-Shrinker verbessern können. Wenn wir beispielsweise eine Liste von zehn API-Calls haben und nach dem fünften API-Call einen Fehler erkennen, könnten wir dem Shrinker sagen, dass er die Liste sofort auf die ersten fünf Elemente kürzen soll. Aber auch ohne diese Anpassungen funktionierte es gut genug.
Was unsere Tests sichtbar gemacht haben
Der Ansatz zahlte sich aus. Wir stießen auf eine ganze Reihe von Abweichungen, darunter:
- Interne Fehler: Es war möglich, einen Zustand zu erreichen, den das Backend nicht erwartet hatte.
- Unterschiedliche Zustände bei Fehlerbedingungen: Schickten wir zum Beispiel einen Reset an einen Server ohne IP-Adresse, war der Server im alten Backend danach ausgeschaltet, im neuen Backend eingeschaltet.
- Zusätzliche erlaubte Aktionen im neuen Backend: In einigen Fällen erlaubte das neue Backend mehr Aktionen als das alte. Zum Beispiel ließ sich eine IPv6-Floating-IP zuweisen, obwohl keine primäre IPv6-Adresse existierte.
- Unterschiedliche Fehlermeldungen zwischen altem und neuem Backend.
- Unterschiedliche Zustände nach mehreren erfolgreichen Aktionen: zum Beispiel Rescue nach change_type oder Rescue in Kombination mit ISO.
Mit klassischen oder manuellen Tests hätten wir einige davon möglicherweise nicht gefunden. Sichtbar wurden sie erst durch die ungewöhnlichen Aktionsketten, die der Generator zusammenwürfelte.

Nach dem Release: Testen ohne altes Backend
Nach dem Rollout stand das alte Backend nicht mehr als Oracle zur Verfügung, also als Referenz, gegen die wir das erwartete Verhalten abgleichen konnten. Deshalb haben wir ein internes Modell für den erwarteten Zustand implementiert. Startet ein Server per API-Call, setzt dieses Modell den Server zum Beispiel auf running. Stimmt der reale Systemzustand nicht mit dem Modell überein, geben wir einen Fehler aus, weil der erwartete Zustand nicht erfüllt wurde.
Warum sich Property-Based Testing für unser Backend-Rewrite bewährt hat
Für unser Rewrite war Property-Based Testing ein nützlicher Teil unserer Teststrategie. Der automatisierte, funktionale und zufallsbasierte Ansatz half uns, vor dem Release mehrere Bugs zu finden – darunter einige, die wir mit manuellen oder deterministischen Tests möglicherweise nicht gefunden hätten.
Gerade für diesen Rewrite passte die Methode gut, weil wir das alte Backend-System als Oracle nutzen konnten. Shrinking reduzierte fehlschlagende Sequenzen auf kleinere Beispiele, die wir leichter reproduzieren und beheben konnten.
Das Shrinking könnte dabei künftig noch weiter ausgebaut werden – abgesehen davon hat sich der Ansatz eindeutig bewährt.




